
Market sentiment analysis
What is market sentiment analysis?
Also known as opinion mining or emotion artificial intelligence, or textual sentiment analysis aims to process and extract the subjective content of descriptive and written work. This objective is achieved through the analysis of the source’s opinions, or their evaluation towards a topic or a product as well as sentiments, attitudes, and emotions.
In trading, investment banks and hedge funds are trying to take advantage of sentiments of the market to help them make better predictions about the financial market. Some of the very accomplished firms including DE Shaw, Two Sigma and Renaissance Technologies have been reported to use sentiment signals. In some of these approaches, sentiment signals are blended in with other data such as transactional data (prices, historical returns or dividends). Sentiment analysis can be performed as stand-alone research prior to traditional trading or it could be equipped into algorithmic trading.
Techniques such as Natural Language Processing and Text Mining are employed in order to perform analysis and the extraction process.
Types of sentiment
Based on the typology proposed by Scherer, there are two types of sentiment while performing sentiment analysis. One type is the “attitude”, which is a narrow definition of sentiment, whether the opinion is “positive” or “negative”.
The second type of sentiment within sentiment analysis is the “emotion”. This indicates the eight “basic emotions”, which are in four opposing pairs, joy-sadness, anger-fear, trust-disgust and anticipation-surprise.
Steps to perform sentiment analysis on market data
Step one: data collection
In order to perform sentiment analysis on market instruments e.g. a stock, there first should be the source to which the data stream flows for sentiment algorithms to start processing. Such data sources are best to be provided through APIs to reach automation in the collection process. One common and widely used source of data for stock market sentiment analysis is Twitter. Through the search query API provided by Twitter, the thrid-party system can query data via the REST API with given conditions such as location, language and time and etc.
Step two: Classifier engine
Once required corpus data created for the sentiment analysis, there should be a step to extract features from the data. Different domains should design classifiers differently since words could mean differently across different industries. Having said that, most of the sentimental words (basically adjectives) are self-explanatory. Some of the methods used to create word classifiers and feature extraction engines are Naive base, Support Vector Machine (SVM) or K-clustering methods.
Step three: predictive modeling
Once the classifier engine is in place, the data scientists will start the process of examining the best predictive models for the data. Which makes this step into two phases, the training, and testing (predicting). during the training phase, the data scientists will train different models and fine-tune them in order to use it for the second phase which is testing which will result in obtaining an accuracy level. This process iterates until there is an acceptable accuracy level determined by domain experts and data scientists. Results of such tests should also be checked if whether they are statistically reproducible or not, basically if the model achieves a similar accuracy level on different datasets throughout time.
Are price and sentiment correlated?
There are numerous researches conducted over this question, nevertheless, the general intuition in the market is that; there is a correlation between sentiment and price in the market. In experimental work with consideration to asses whether the financial market reacts to relevant news events, the sentiment analysis was performed using both a standard model and an enhanced temporal model. Within the temporal test, they associate the sentiments with the corresponding temporal orientations by classifying each sentence with one of the four temporal categories (past/present/future/unknown) and calculate the sentiment strength accordingly.
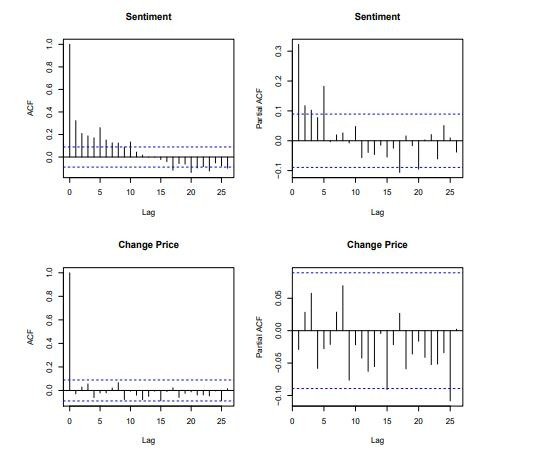
The result of this practice concluded that the casualty test experiment, two competing hypotheses that market sentiment cause price changes and vice versa were approved. In most research cases it is not clear which is the cause and which is the effect.
Challenges
Even though the correlation between price and sentiment in the market can be seen but predict the price of stocks is the hard part. Many types of research have been conducted in this field and results are somewhat average.
Though another significant challenge linked to the sentiment analysis approach to the stock market is the notion of opinion expressing words. Some words can be perceived as either positive or negative depending on the context they are used, e.g the word short could be used in latency and indicates a positive message.


