Machine Learning in Finance
It’s known that almost all industries are influenced or about to be influenced by the appliance of Artificial Intelligence. Perhaps operational efficiency is what makes Artificial Intelligence so attractive for business owners across different sectors. Operational efficiency could lead to the reduction of costs, increased performance, speed up some processes or increase the quality of services.
In this article, we would like to cover the appliance of Machine Learning across the financial industry by presenting interesting use cases and examples to structure this content.
Artificial Intelligence is assisting financial institutions to drive new efficiencies and deliver new kinds of value. Autonomous Research predicts that Artificial Intelligence will represent $1 trillion in projected cost savings for the banking and financial services industry. By 2030, traditional financial institutions will save 22% of costs.
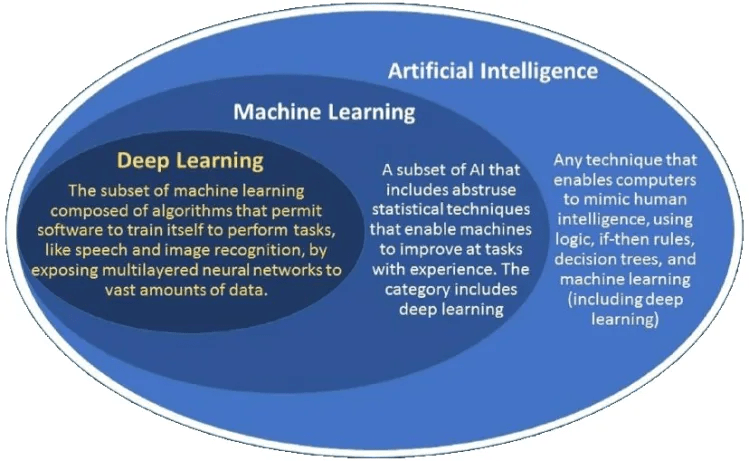
Let’s get something straight here and let’s define Machine Learning vs Artificial Intelligence. These two terms are always used side by side of each other, but they are different. With different, we mean that Machine Learning is a subset of Artificial Intelligence. Artificial Intelligence refers to create intelligent machines. Machine Learning refers to a system that can learn from experience. In this article, we may mention both but with the given simplistic definition you already know what we are referring to.
Challenges of applying Artificial Intelligence in finance
Before jumping into the use cases that we have gathered for this article, let’s take a look at the most common challenges of applying Artificial Intelligence in firms within the financial industry.
As previously mentioned costs and budgeting required to automate some of the processes in finance could be one of the main important challenges financial firms face. Additionally, regulatory requirements sometimes could be also a burden. They are complex frameworks and the required research phase could be time-consuming and hiring regulatory consultants could be costly.
Perhaps another challenge these firms face is the lack of structured or sufficient data to process and train their data and test if models are efficient enough. Adding to that lack of in-house skills and knowledge as well as missing the development environment (lab) that data scientists can join and apply approaches of AI.
Another challenge could also come from market maturity and retail readiness to use Artificial Intelligence-powered tools.
Case 1. Fraud detection
One of the very important appliances of Machine Learning in finance is fraud detection. With the advent of instant payment and global transfer services, the volume of payments and transfers has dramatically increased. So is a notable amount of transfers that aren’t with good intentions including money laundering. The estimated amount of money laundered globally in one year is 2-5% of global GDP, or $800 billion to $2trillion.
An advantage that Machine Learning has brought to fraud detection is the amount of data that can be processed by machines with minimum or zero human intervention. The appliance comes with more accuracy in the detection of fraudulent activities.
For instance, the credit card fraud detection problem includes modeling past credit card transactions with the knowledge of the ones that turned out to be a fraud. This model is then used to identify whether a new transaction is fraudulent or not. The aim here is to detect fraudulent transactions while minimizing incorrect fraud classifications. Anomaly detection is a commonly used model for the credit card fraud detection problem, this is a technique used to identify unusual patterns that do not conform to expected behavior, called outliers. Anomaly detection or pattern recognition algorithms start with creating processes that find the hidden correlation between each user behavior and classify the likelihood of fraudulent activity.
Discovering hidden and indirect correlations can be named as advantages that Machine Learning based algorithms bring compare to basic Rule-based fraud detection algorithms. Machine Learning-based algorithms also reduce the number of verification measures since the intelligent algorithms fit with the behavior analytics of users. A more automated approach to detection of fraud is also another asset for Fraud Detection algorithms applied by Machine Learning since they require less manual work to enumerate all possible detection rules.
Case 2. Know Your Customer (KYC)
Improving the KYC process is one of the operational efficiency of artificial intelligence and machine learning algorithms that have been brought to the financial and banking industry. The appliance of Machine Learning on the KYC process is mostly implemented by traditional banks and neobanks. The main reason is the continuous evolvement of requirements from regulators. The due diligence required on customer registration that is required by regulators in banking is broad and complex. Machine Learning due diligence modules can be utilized to create robust automation and improve the process of KYC for institutions that are aiming to have an efficient retail onboarding. This will decrease the human intervention needed during the onboarding process and increases the accuracy as well as reducing the costs.
Again neobanks are streamlining the KYC process with enhanced user interface and user experience. Simplifying and automating the KYC process can reduce the cost of onboarding and customer application process by 40% (source Thomson Reuters).
One of Machine learning techniques used in the KYC process is the Facial Similarity check, which is to verify that the face in the picture is the same with that on the submitted document provided e.g. Identity Card. The customer will only be verified and pass the KYC process if the results of both Document and Facial Similarity checks are ‘clear’. If the result of any check is not ‘clear’, the customer has to submit all the photos again.
Case 3. Algorithmic Trading
The algorithmic trading with a technological infrastructure brought many advantages to the trading world e.g. the ability to trade in under a millisecond with the best prices available or the ability to simultaneously monitor and trade across multiple exchanges, and all with reducing the human error from trading. Algorithmic trading constitutes 50-70% of the equity market trades and 60% of futures trades in developed markets.
Many hedge funds started to utilize Artificial Intelligence within the algorithmic trading world. It’s understandable that most of them do not disclose the details and mechanism of their approaches in applying Artificial Intelligence in their trading algorithms, but it’s understood that they use methods of Machine Learning and Deep Learning. There is also a wide appliance of sentiment analysis on the market in which the result can be used in trading. The main objective of applying sentiment algorithms is to obtain knowledge about the psychology of the market.
Machine Learning is assisting the trading industry in order to leverage the market with fundamental and alternative data in order to research alpha factors. Supervised, unsupervised and reinforcement learning models are being utilized to enhance the processing of algorithmic trading strategies. Methods can be applied to optimize portfolio risk calculations and further improve the performance of the portfolios.
Deep Learning models also have been widely applied in trading. Deep learning models with multiple layers have shown as a promising architecture that can be more suitable for predicting financial time series data. In a tested practice, the algorithm trains 5-layer Deep Learning Network on high-frequency data of Apple’s stock price, and their trading strategy based on the Deep Learning produces 81% successful trade and a 66% of directional accuracy.
Case 4. Chatbots and customer support
Reducing customer churn is perhaps one of the main criteria of financial institutions and banks. Generally, customers and especially millennials ones for neobanks do care about the customer service and support they receive. Chatbots and instant messaging apps could potentially increase communication quality between business and its customers. According to research by Juniper by the year 2023, the use of chatbots can reduce the operational costs for banking, retail, and healthcare business sector by $11 billion.
The advantages that chatbots can bring to the industry are definitely increasing customer satisfaction and customer engagement rates. The speed of action and processing of many inquiries and threads at the same time could also be mentioned as a big advantage of chatbots and messaging systems.
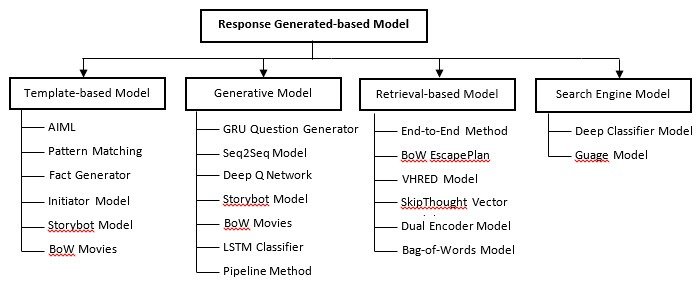
There are four types that Chatbots could be classified. Goal-based Chatbots, are designed for a particular task and set up to have a short conversation in order to complete a task given to them by a user. Perhaps this is the most common Chatbot. Goal-based Chatbots are deployed on websites to help visitors to answer their questions during their visit.
The second type is knowledge-based Chatbots, these Chatbots use the underlying data sources or the amount of data they are trained on. Such data sources could be open-domain or cloud domain data. Usually, Knowledge-based Chatbots answer questions by providing the data and source of that data.
The third category of Chatbots is Serviced-based. Such Chatbots are classified based on facilities provided to the customer. It could be personal or commercial information. Users of such Chatbots could place an order of a commercial good via the Chatbot.
The fourth category is Response-generated Chatbots. Response Generated-based chatbots are developed based on what action they perform in response generation. The response models take input and output in natural language text. The dialogue manager is responsible for combining response models together. To generate a response, the dialogue manager follows three steps.
Case 5. Automated Wealth Management with Robo Advisors
Wealth management is an industry and operation costs are a large burden for some of the firms. As wealth being transferred from one generation to a more tech-savvy one and considering the millennials are in their prime earning and spending years, the presence of automated and entirely digital investment advice tools can be expected. It’s expected that by the year 2022 the Robo Advisors revenue might reach 25 billion that is up from $1.7 billion from 2017, considering these tools are relatively cheaper to how the investment advice is being delivered traditionally, from 3% to 5% of assets managed to digital ones with 0.25% to 0.75%.
There are practiced used cases where the processes of asset allocation modeling, portfolio construction, and optimization, as well as a portfolio recommendation systems, were bundled with Machine Learning techniques in order to enhance the current approaches.
One example is the portfolio recommendation system that was designed to be implemented on top of a Robo Advisor and be utilized with the mean-variance optimization method was implemented using weighted linear regression. The model shows that adding a portfolio layer on top of the stock regression results is increasing the success rate (profit accuracy) up to 86.69% when success is calculated by the profitability of the recommendations. Moreover, it helps to reduce the risk by distributing the budget over a set of stocks and tries to minimize the reflection of the regression errors to the profit.
Robo Advisors come with many notable advantages, such a complete, online and real-time reporting dashboard to customers which can be checked on the go with mobile apps and dashboards.
As previously mentioned they reduce the costs of operations for firms providing investment advice service and the fees that are clients charged. Robo Advisors are fully digital and they have online onboarding for clients which leads to expansion of client base for firms.
When can you apply AI (is your firm ready?)
There are few aspects to which we could measure the readiness of a firm to utilize Artificial Intelligence and Machine learning into their processes. A solid technological infrastructure is the most important element. An infrastructure that is put together to manage the whole lifecycle of data, from getting to cleaning to processing and feeding algorithms. The availability of the data can not be stressed more.
The regulatory compliance as mentioned in some of the cases above e.g. in KYC processes is a crucial process to be taken care of before applying Artificial Intelligence into processes. Audit trails, transparency, result supervision, and reporting mechanisms are some of the high-level requirements from financial authorities.
Talents as resources from data engineers to data scientists specialized and familiar with financial processes is another important criteria before kick-starting with Artificial Intelligence projects. Their ability to understand the sector and ways to improve it should be taken into account in their hiring process. Eventually, they need to start training the existing data with an accuracy level as a requirement for the models used.
How to start your machine learning project?
- Start with a question
Before anything starts you need to start with the question, what is it that we want to improve with our Machine Learning algorithms? This should specify and clarify the objective of the project.
- Understand your data
Not every question can be answered with any data. You need to have the right data for the right question. This is practiced by receiving, cleaning and processing data. Running exploratory analysis on your data and making sense of some of the summaries obtained could be the initial stage to which you will know that if your data has the potential to answer your questions.
- Modeling
Once you found clues in your data associated with your question it’s time to try to write algorithms to find patterns that leads to successful or unsuccessful journeys. Usually, data scientists do this by fitting the most suitable Machine Learning models into the data, find correlative and statistically significant patterns and try to test the accuracy.
- Evaluation
In the modeling section, we talked about training your data and once we have found the best models that suit the question, the answer and the data and now its time to evaluate, in other words, test your models. Data scientists will keep on testing the models with new data to see if their models do not only work for one dataset.
- Deployment
Once the fitting algorithms are certain that works, it’s time to deploy. Generally, this means deploying a code representation of the model into an operating system to score or categorize new unseen data as it arises and to create a mechanism for the use of that new information in the solution of the original business problem. Importantly, the code representation must also include all the data preparation steps leading up to modeling so that the model will treat new raw data in the same manner as during model development.
Schedule your appointment right now to learn more